README
Introduction:
This is Matlab and Julia code for (re)producing the figures in the paper
"Adaptive restart of the optimized gradient method for convex optimization,"
Donghwan Kim and Jeffrey A. Fessler, 2017
[http://arxiv.org/abs/1703.04641]
Published in
JOTA Jul. 2018 [http://doi.org/10.1007/s10957-018-1287-4]
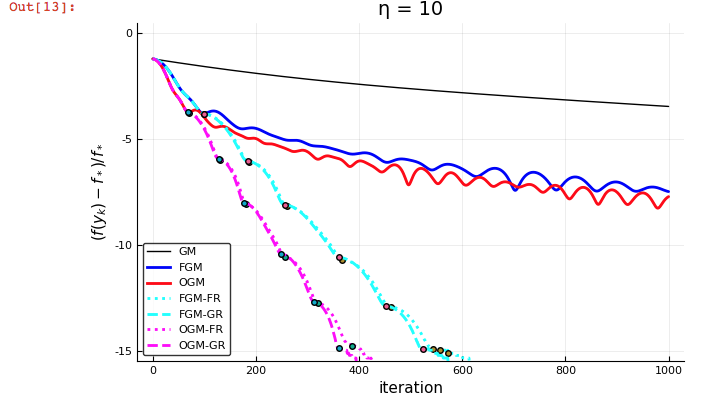
The empirical results show that adaptive restart provides very beneficial acceleration of the optimized gradient method (OGM) and that OGM with restart converges faster than Nesterov's fast gradient method (FGM) with restart.
The methods are generally applicable to convex problems with Lipschitz gradients and to composite convex cost functions. Anyone using FISTA should try POGM with restart instead!
If you use this code, please cite the JOTA paper linked above.
The code is distributed per the Creative Commons Attribution 4.0 license: https://creativecommons.org/licenses/by/4.0/
git clone git@gitlab.eecs.umich.edu:michigan-fast-optimization/ogm-adaptive-restart
Contents:
-
Functions executing accelerated gradient methods (with restart) for smooth convex minimization:
-
mfile/gm_restart.m -
jl/gm_restart.jl -
Functions executing accelerated "proximal" gradient methods (with restart) for nonsmooth composite convex minimization:
-
mfile/pgm_restart.m -
jl/pgm_restart.jl -
Five demos in [KF17a] can be demonstrated by each file below:
-
mfile/demo1_str_cvx_case1.m: usesgm_restart.m -
mfile/demo2_str_cvx_case2.m: usesgm_restart.m -
mfile/demo3_logsumexp.m: usesgm_restart.m -
mfile/demo4_sparselr.m: usespgm_restart.m -
mfile/demo5_quad.m: usespgm_restart.m
-
-
Jupyter notebooks (using Julia 0.7 or later) to generate similar figures:
-
jl/fig_*.ipynbusegm_restart.jlandpgm_restart.jl
-
-
The "fig" directory has the figures that result from all the demos and that correspond to the figures in the paper.
The results of these demos are figures that look like the following, that illustrate that OGM and POGM are faster than Nesterov's fast gradient method (FPGM) and than FISTA.
[KF17a] D. Kim, J.A. Fessler, "Adaptive restart of the optimized gradient method for convex optimization," Arxiv:1703.04641, (2017)
[KF18] D. Kim, J.A. Fessler, "Adaptive restart of the optimized gradient method for convex optimization," JOTA 178(1):240-63, Jul. (2018) [http://doi.org/10.1007/s10957-018-1287-4]
Copyright 2017-03-31, Donghwan Kim and Jeff Fessler, University of Michigan